



Maintaining a pleasant online ordering experience involves ensuring that large search indexes remain effective at scale. For DoorDash this was a particular challenge as the number of stores, items, and other data increased every day. Under this load, it could take up to a week to reindex all of the changes and update our search database.
We needed a fast way to index all of our platform’s searchable data to improve product discovery, ensuring that we offered consumers all available ordering options. In addition, this project would also increase the speed of experimentation on our platform so we could improve our search performance more quickly.
Our solution involved building a new search indexing platform that uses incremental indexing on our data sources. We based this platform on three open source projects, Apache Kafka, Apache Flink, and Elasticsearch.
DoorDash’s problem with search indexing
Our legacy indexing system was not reliable or extensible, and it was slow. A reliable indexing system would ensure that changes in stores and items are reflected in the search index in real time. Incrementally indexing helps refresh data faster, building fresh indexes to introduce new analyzers and additional fields in shorter amounts of time, which ultimately helps improve retrieval.
Teams from new business verticals within DoorDash wanted to build their own search experience but didn’t want to reinvent the wheel when it came to indexing the search data. Therefore, we needed a plug-and-play solution to improve new search experiences without slowing down development for these business vertical teams.
Building an event-driven pipeline for indexing documents
We solved these problems by building a new search indexing platform that provides fast and reliable indexing to power different verticals while also improving search performance and search team productivity. It uses Kafka as a message queue and for data storage, and Flink for data transformation and sending data to Elasticsearch.
High-level Architecture
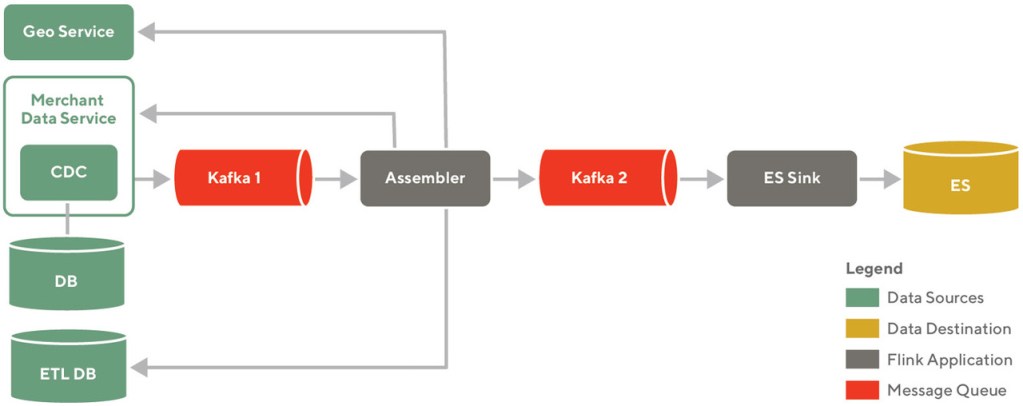
Figure 1, above, shows various components in our search index pipeline. The components are grouped into four buckets:
- Data sources: These are the systems which own CRUD operations on the data. We call them the source of truth for the data. In our stack we utilized Postgres as the database and Snowflake as the data warehouse.
- Data destination: This is the data store which has been optimized for search. In our case we chose Elasticsearch.
- Flink application: We added two custom Flink applications in our indexing pipeline, Assemblers for transforming data and Sinks for sending data to the destination storage. Assemblers are responsible for assembling all the data required in an Elasticsearch document. Sinks are responsible for shaping the documents as per the schema and writing the data to the targeted Elasticsearch cluster.
- Message queue: We used Kafka as our message queue technology. The Kafka 2 component, from Figure 1, above, uses the log compacted and preserved indefinitely topics.
Bound together, these components comprise an-end to-end data pipeline. The data changes in data sources are propagated to Flink applications using Kafka. Flink applications implement business logic to curate search documents and write those to the destination. Now that we understand the high level components, let’s go through the different indexing use cases.
Subscribe for weekly updates
Incremental indexing
The indexing pipeline processes incremental data changes from two different sources. The first one captures the data changes as they happen in real time. Typically, these events are generated when human operators make ad hoc changes to stores or items. The second one is ETL data changes. Our machine learning models generate ETL data in a data warehouse. The indexing pipeline handles events from these two data sources differently.
Indexing change data capture (CDC) events
DoorDash’s data about merchants gets created and updated continuously, and needs to be addressed by our index pipeline solution. For example, these updates can be anything from merchant operators adding tags to a store to updating menus. We need to reflect these changes on the consumer experience as quickly as possible or consumers will see stale data in the application. These updates to the platform are saved in data stores such as Postgres and Apache Cassandra. Iterative workflows also crunch the data in the data warehouse with daily cadence, powering things such as business intelligence applications.
To reliably capture these update events from a service’s database, we explored enabling change data capture (CDC) for Aurora/Postgres using Debezium connector, a Red Hat-developed open source project for capturing row-level changes. The initial performance testing carried out by the storage team suggested that this strategy had too much overhead and was not performant, especially when the service uses the same database for serving online traffic. Therefore, we implemented save hooks in the application, which are responsible for handling data update requests, to propagate change events through Kafka whenever there is a change on the underlying data store. We call this approach Application Level CDC.
With Application Level CDC, we could run into consistency issues. A distributed application has multiple instances. Two separate update calls may get served via two different instances. If we include updated values in the Kafka messages, it wouldn’t guarantee consistency and solve the issue because in certain cases multiple instances of the application will push events that are updating the same value.
For example if Application instance #1 sends an event, {store_id: 10, is_active=true}, and Application instance #2 sends an event, {store_id: 10, is_active=false}, there would be conflicts on the consumer side.
To ensure consistency, we send only changed entity IDs in the Kafka events. Upon receiving the Kafka events, our Assembler app calls REST APIs on the application to gather other information about entities which are present in Kafka events. The REST API calls ensure data consistency about the entity. The Assembler amalgamates the information to create an event which it pushes to Kafka for the Sink app to consume. The Assembler implements a windowed dedupe, which prevents calling REST APIs for the same entity multiple times within a specified amount of time. The Assembler also does aggregation of events in order to call REST endpoints in bulk. For example, over a period of 10 seconds, it aggregates item updates for a store. It calls REST APIs for that store including all of the deduped and aggregated items.
To summarize, we use the Application Level CDC to capture data change events. We resolve consistency issues with simplified events and REST APIs. We use dedupe and window functions to optimize the event processing.
Indexing ETL data
Many properties of the store and item documents that are critical to our retrieval process, such as scores and tags generated by ML models, are updated in bulk once a day. This data is either model generated, as when an ML model runs the freshest data, or manually curated, as when our human operators manually tag items with “chicken” for a particular store. This data gets populated into tables in our data warehouse after a nightly run of the respective ETL jobs.
Before our new search index platform, we did not have a reliable way of uploading data onto our index, instead using slow and imprecise workarounds. We wanted to improve our existing pipeline by giving our new search index platform the mechanism to reliably ingest ETL data into our index within 24 hours.
The CDC patterns for the ETL use case are very different from the incremental update case described in the previous section. In the case of incremental updating, the merchant data stores are constantly being updated, resulting in a continuous stream of updates over the course of the day. On the other hand, for the ETL use case, the updates occur all at once when the ETL runs, with no other updates until the next run.
We decided not to use a variant of the Application Level CDC for the ETL sources because we would see large spikes in updates everytime the ETL ran, and this spike could overly stress our systems and degrade performance. Instead, we wanted a mechanism to spread out the ETL ingestion over an interval so that systems don't get overwhelmed.
As a way forward, we developed a custom Flink source function which periodically streams all the rows from an ETL table to Kafka in batches, where the batch size is chosen to ensure that the downstream systems do not get overwhelmed.
Sending documents to Elasticsearch
Once the Assembler applications publish data to destination topics, we have a consumer that reads the hydrated messages, transforms the messages according to the specific index schema, and sends them to their appropriate index. This process requires management of the schema, index, and cluster. We maintain a unique Kafka consumer group per ElasticSearch index so that consumers can maintain offsets for each index. To transform messages, we use a DocumentProcessor(s), which takes in a hydrated event from the destination topic and outputs formatted documents that are ready to be indexed.
The Sink process utilizes Flink Elasticsearch Connector to write JSON documents to Elasticsearch. Out of the box, it has rate limiting and throttling capabilities, essential for protecting Elasticsearch clusters when the system is under heavy write load. The process also supports bulk indexing where we gather all documents and the relevant operations over a time window and perform bulk requests. Any failure to index a document results in the document being logged and stored in a dead-letter queue which can be processed later.
Backfilling a new index quickly
Oftentimes, we might want to add a new property to our index, such as adding the market ID associated with a store or item to the document because it helps us in sharding. Likewise, we may need to rapidly recreate a new index, such as when we want to try out different index structures to run efficiency benchmarks.
In the legacy system we relied on a slow and unreliable job that typically took a month to reindex all the store and item documents. Given the long indexing duration, it was difficult to properly estimate the error rate associated with the reindexing process. Thus, we were never certain of the indexing quality. We often got complaints about mismatches in store details between the index and the source of truth, which had to be fixed manually.
With our new search index platform, we wanted a process to rapidly recreate a new index or backfill a property in an existing index within 24 hours. For the process of bootstrapping, we needed a mechanism to rapidly recreate all the documents which needed to be indexed in Elasticsearch. This process involves two steps:
- Streaming all entity IDs corresponding to the documents which needed to be indexed in ElasticSearch
- Mapping the entity IDs to their final form by making external calls before they are sent downstream for indexing.
The pipeline for mapping the entity ID to the final form of the entity had already been established as part of our work on the online assembler, mentioned above. Therefore, all that was needed was to stream all the document IDs which needed to be indexed in Elasticsearch. Accordingly, we maintain an up-to-date copy of all the entity IDs which need to be indexed in bootstrap tables in our data warehouse. When we need to bootstrap, we use the source function described in the ETL section to stream all the rows from these bootstrap tables to Kafka. We encapsulate the logic to perform the above two steps in a single job.
If we run our incremental indexing pipeline at the same time as our bootstrapping pipeline, we run the risk of getting stale data in Elasticsearch. To avoid these issues, we scale down our incremental indexer everytime the bootstrap is being run, and scale it back up once the bootstrap is complete.
Putting it all together, the steps we take to backfill and recreate the index are as follows:
- Create the index and update its properties as needed, and update the business logic and configurations in the assembler and the sink to populate the new property.
- Scale down the online assembler.
- Scale up the bootstrap job.
- Once the bootstrap is complete, scale down the bootstrap job and scale up the online assembler. Once the offset becomes recent, the bootstrap process is complete.
Enabling a forced reindexing function
From time to time, some of our documents in Elasticsearch might have stale data, possibly because some events from upstream didn’t get delivered, or one of our downstream services took too long to respond. In such cases, we can force a reindex of any documents in question.
To accomplish this task, we send a message with the ID of the entity to be indexed into the topic which the online assembler consumes data from. Once the message is consumed, our indexing pipeline described above gets kicked off, and each document is reindexed in Elasticsearch.
We annotate the messages being sent in our one-off indexing tasks with unique tags which provides us with a detailed trace of the document as it passes through the various stages of the indexing flow. In addition to providing us with a guarantee that the document did indeed get indexed, it provides us a wealth of debugging information which helps us validate and helps uncover any bugs which might have prevented it from being indexed in the first place.
Results
Our new search indexing platform is more reliable. The incremental indexing speed helps refresh data faster and appears more promptly in our consumer applications. Faster reindexing enabled fresh indexes to be built in a short amount of time to improve our retrieval:
- Reduced the time for backfilling our entire catalog of stores from one week to 6.5 hours
- Reduced the time for backfilling our entire catalog of items from two weeks to 6.5 hours
- Reduced the time to reindex existing stores and items on the platform from one week to 2 hours
Conclusion
Data lives at the heart of any organization. Moving data seamlessly and reshaping it for different use cases is an essential operation in our microservice architecture. This new search index platform lets other teams at DoorDash design search experiences for specific business lines without having to build a whole new search index architecture. Our reliance on open source tools for this search index means a lot of accessible documentation online and engineers with this expertise who might join our team.
Generally, this kind of solution applies to any company with a large, growing online catalog that is focused on making changes to its search experience. By taking a similar approach as described above, teams can cut down on the reindexing time and allow faster iterations and less manual interventions while improving the accuracy of their index. Our approach is particularly beneficial to companies that have a rapidly growing catalog and multiple manual operators making changes that need to be reflected in the index.
Header photo by Jan Antonin Kolar on Unsplash.












 WayneCunningham
WayneCunningham
Very useful and important
Is this is a platform how do you onboard new customers? Is it a white glove support or self-onboarding? How do you detect that there is a need to re-index the data? Do you use any sort of auditing? Plus how do ensure that SLAs’ are met for the data being indexed? Also what is the size of dataset?